UILabel の改行をいい感じにする実験
この記事は Goodpatch Advent Calendar 2019 の16日目です.
API から動的にテキストを取得する場合,改行の位置を制御することはむずかしいです. UILabel には Word Wrap の機能がありますが,日本語では使えません. そこで,なんとか自力で改行格好悪い問題に対処できないか,実験をしてみました.
概要
- iOS SDK の自然言語処理で単語の区切りを取得する
- UILabel の改行位置を取得する
- テキストの改行が単語の途中で挟まらないように自分で改行を挟んでから流し込む
という方針で試していきます.実験に使ったソースコードは GitHub にあります.
thedoritos/NaturalLabel: Experiment to break line naturally in UILabel
環境
- iOS Simulator iOS 13
通常のレイアウト
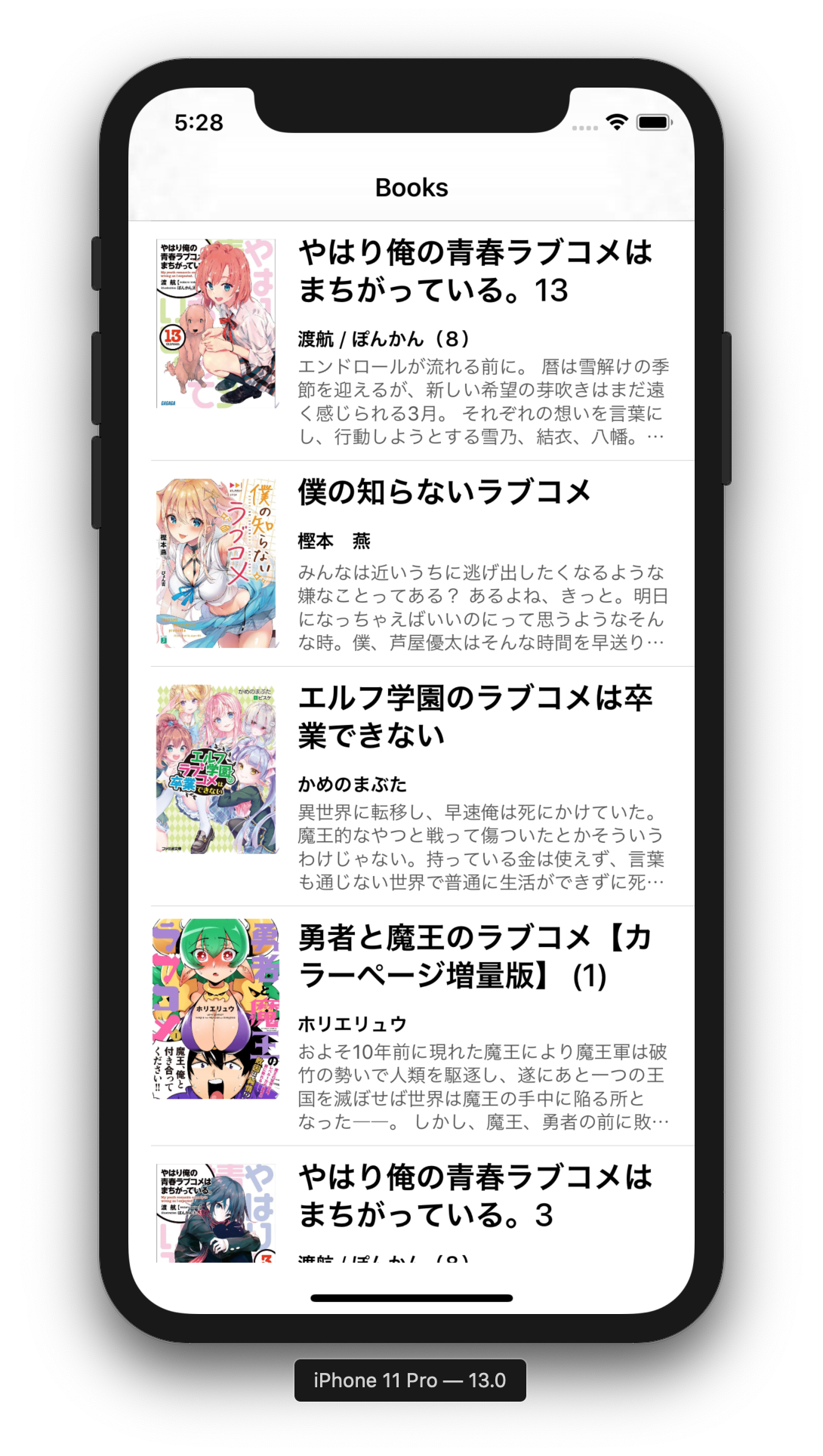
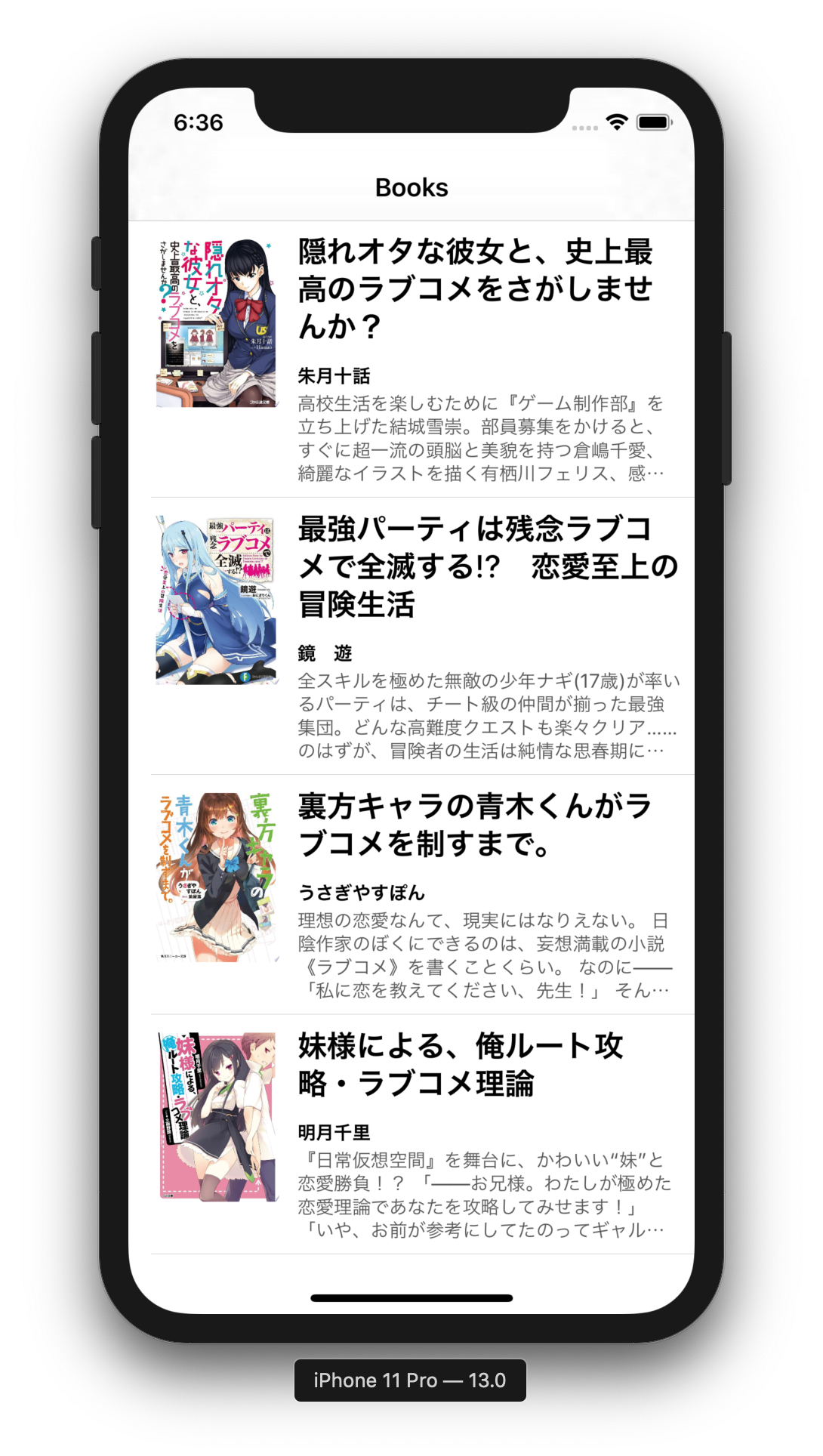
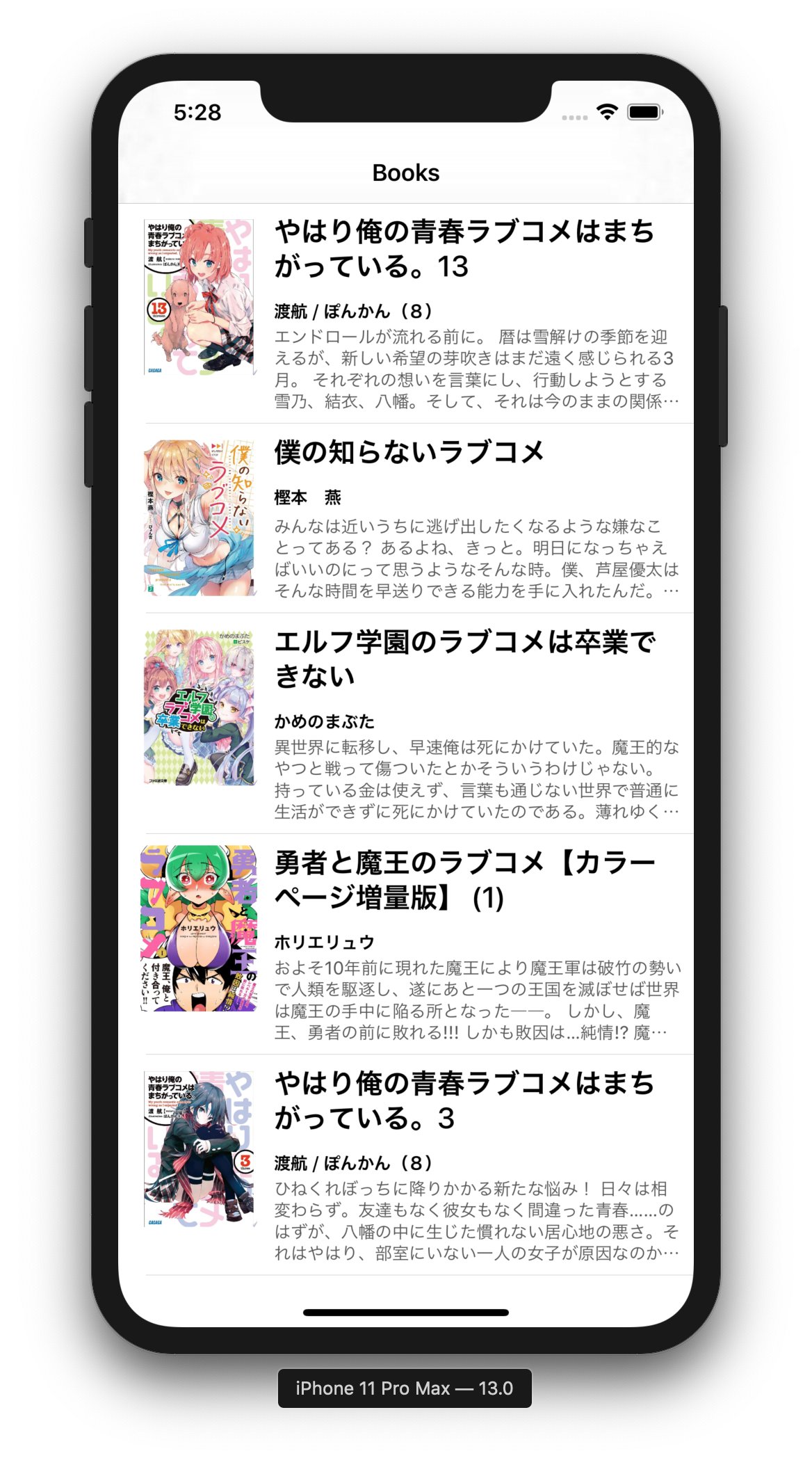
まず,お題となるアプリを用意するために,通常どおり UILabel を使って標準的なレイアウトをしてみます.
Google Books API を使って適当な書籍の情報を取得して TableView に表示しました.
| iPhone 11 Pro | iPhone 11 Pro Max | ||
|---|---|---|---|
 |
 |
 |
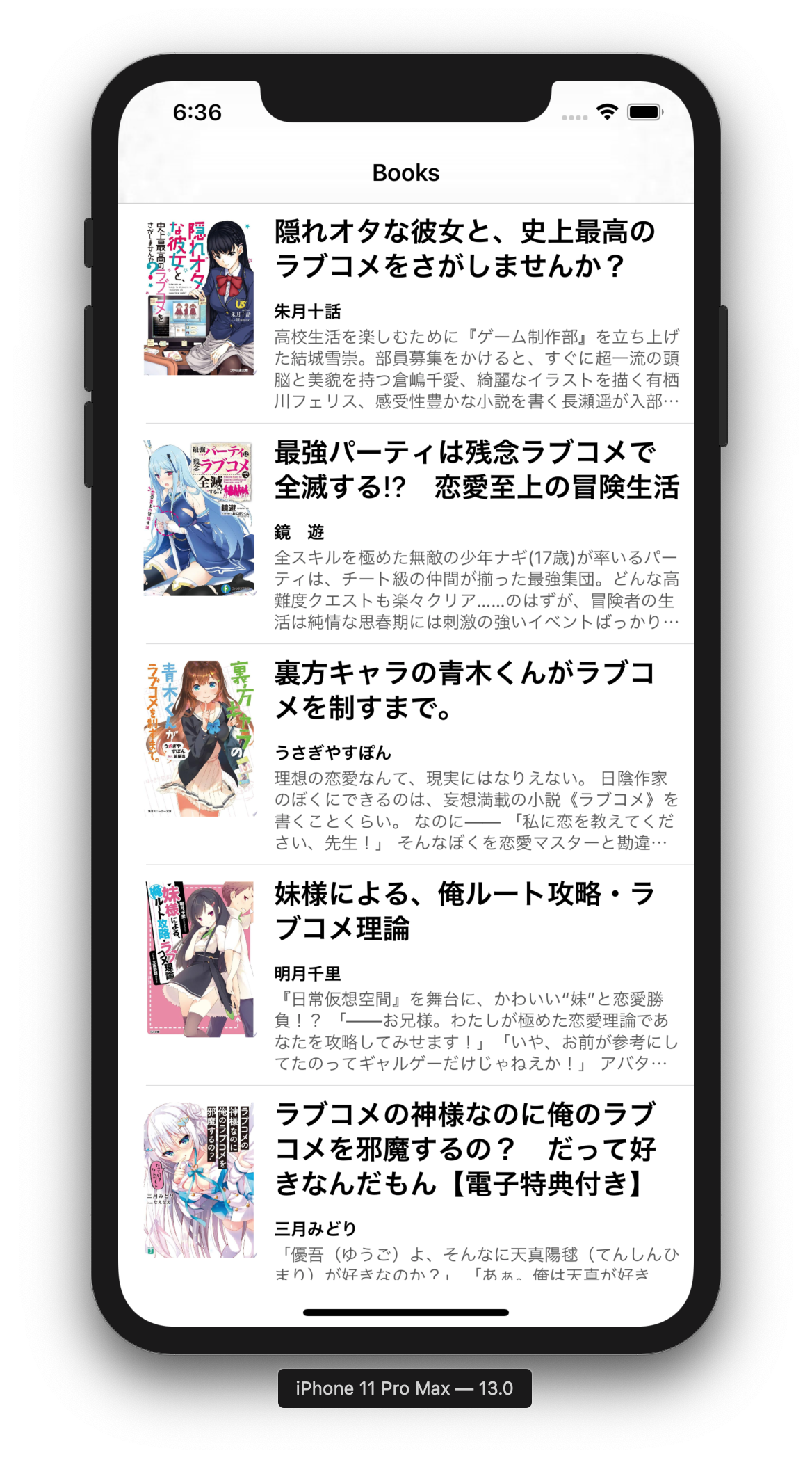 |
意外とそんなに気にならない結果になったような気もします.
完!!!
…では実験にならないので,もう少しいい感じにできる余地があるか試していきます. 今回は次の3タイトルをベンチマークとして調整していきます.
やはり俺の青春ラブコメはまちがっている。14隠れオタな彼女と、史上最高のラブコメをさがしませんか?裏方キャラの青木くんがラブコメを制すまで。
遊びなので妥当性は気にしません. 目についたものを選んだだけで他意はありません.
Natural Language
iOS には端末で自然言語処理を行える Natural Language Framework があります. これを使って日本語の改行を「いい感じ」にすることができないか試してみます.
Tokenizing Natural Language Text
まずは文庫本のタイトルを単語単位に分割してみます. ドキュメントの Tokenizing Natural Language Text に従って次のようにしました.
import UIKit
import NaturalLanguage
class NaturalLabel: UILabel {
func naturalize() {
guard let text = self.text else { return }
debugPrint(text)
let tokenizer = NLTokenizer(unit: .word)
tokenizer.string = text
let tokens = tokenizer.tokens(for: text.startIndex..<text.endIndex)
let words = tokens.map({ text[$0] })
debugPrint(words)
}
}
3タイトルはそれぞれ次のように分割できました.
"やはり俺の青春ラブコメはまちがっている。14"
["やはり", "俺", "の", "青春", "ラブコメ", "は", "まちがっ", "て", "いる", "14"]
"隠れオタな彼女と、史上最高のラブコメをさがしませんか?"
["隠れ", "オタ", "な", "彼女", "と", "史上", "最高", "の", "ラブコメ", "を", "さがし", "ませ", "ん", "か"]
"裏方キャラの青木くんがラブコメを制すまで。"
["裏方", "キャラ", "の", "青木", "くん", "が", "ラブコメ", "を", "制", "す", "まで"]
単語の途中で改行がはさまらないようにできれば,「まち\nがっている」「史上最\n高」「ラブコ\nメ」といった不自然な改行は改善できそうです. 一方で,「まちがっ\nている」「史上\n最高の」「制\nすまで」といった,間違いとは言えないが少し気持ち悪いかな(個人の感想です)という改行を防ぐことはできなさそうです.
Identifying Parts of Speech
もう少し手がかりを得るために,各単語(品詞)の種類を取得してみます. 再びドキュメントの Identifying Parts of Speech を参考にして次のようにしました.
class NaturalLabel: UILabel {
func naturalize() {
guard let text = self.text else { return }
debugPrint(text)
let tagger = NLTagger(tagSchemes: [.lexicalClass])
tagger.string = text
let options: NLTagger.Options = [.omitPunctuation, .omitWhitespace]
let tags = tagger.tags(in: text.startIndex..<text.endIndex, unit: .word, scheme: .lexicalClass, options: options)
let words: [(String, String)] = tags.map({ (tag, range) in
guard let tag = tag else { return (String(text[range]), "Unknown") }
return (String(text[range]), tag.rawValue)
})
debugPrint(words)
}
}
3タイトルはそれぞれ次のようにタグ付けされました.
"やはり俺の青春ラブコメはまちがっている。14"
[("やはり", "OtherWord"), ("俺", "OtherWord"), ("の", "OtherWord"), ("青春", "OtherWord"), ("ラブコメ", "OtherWord"), ("は", "OtherWord"), ("まちがっ", "OtherWord"), ("て", "OtherWord"), ("いる", "OtherWord"), ("14", "OtherWord")]
"隠れオタな彼女と、史上最高のラブコメをさがしませんか?"
[("隠れ", "OtherWord"), ("オタ", "OtherWord"), ("な", "OtherWord"), ("彼女", "OtherWord"), ("と", "OtherWord"), ("史上", "OtherWord"), ("最高", "OtherWord"), ("の", "OtherWord"), ("ラブコメ", "OtherWord"), ("を", "OtherWord"), ("さがし", "OtherWord"), ("ませ", "OtherWord"), ("ん", "OtherWord"), ("か", "OtherWord")]
"裏方キャラの青木くんがラブコメを制すまで。"
[("裏方", "OtherWord"), ("キャラ", "OtherWord"), ("の", "OtherWord"), ("青木", "OtherWord"), ("くん", "OtherWord"), ("が", "OtherWord"), ("ラブコメ", "OtherWord"), ("を", "OtherWord"), ("制", "OtherWord"), ("す", "OtherWord"), ("まで", "OtherWord")]
全て OtherWord という手がかりゼロの結果になりました.
ちなみに英語だと NLTag の種類どおりにタグ付けされるのですが,日本語だと文字通り何の成果も得られませんでした.
ということで,気を取り直して単語の切れ目だけを手がかりとして進めます.
通常の改行位置を取得する
まずは通常の UILabel に流し込んだ String がどの位置で改行されるのかを取得します. iOS にはテキストをローレベルで触れる Core Text Framework があるので,ドキュメントを読みながら各行を取得するメソッドを書きました.
class NaturalLabel: UILabel {
private func getLines(from text: String) -> [String] {
guard let font = self.font else { return [] }
let attributedString = NSMutableAttributedString(string: text)
attributedString.addAttribute(.font, value: font, range: NSRange(location: 0, length: attributedString.length))
let frameSetter = CTFramesetterCreateWithAttributedString(attributedString)
let framePath = CGPath(rect: CGRect(x: 0, y: 0, width: self.frame.width, height: CGFloat.greatestFiniteMagnitude), transform: nil)
let frame = CTFramesetterCreateFrame(frameSetter, CFRange(), framePath, nil)
guard let lines = CTFrameGetLines(frame) as? [CTLine] else { return [] }
return lines.map({ line in
let cfRange = CTLineGetStringRange(line)
let nsRange = NSRange(location: cfRange.location, length: cfRange.length)
return NSString(string: text).substring(with: nsRange)
})
}
}
最終的には CTLine の Array が欲しい > CTFrameGetLines を呼び出したい > CTFrame が欲しい > CTFramesetterCreateFrame を呼び出したい > … という感じでドキュメントを辿っていけば良いです.
いい感じの改行をする
ようやく準備が整ったので,改行のロジックを考えて実装します. 今回は遊びということでパッと思いついたもので実装していきます.
- 文字列を tokenize する
- 文字列を UILabel に流し込んで改行位置を取得する
- Token を先頭から順に改行位置との衝突が起こるまで読んでいく(例:「ラブ\nコメ」で衝突)
- 衝突が起こる直前までの文字列を確定させて,確定行の String 配列に積む
- 衝突が起こる直前までの token を消費して,判定対象の token から除く
- 残りの文字列を UILabel に流し込んで改行位置を取得する
- 3-6 を token がなくなるまで繰り返す
- 残った文字列を確定行配列に積む
- 確定行配列を改行
\nで join する
日本語にすると難しいですが,コードだったらまだ分かりやすいかもしれません. 実験用なので,衝突判定を String#contains で雑にやっていたり,文字列が長いときのパフォーマンスなどは考慮していません.
class NaturalLabel: UILabel {
func naturalize() {
guard let text = self.text?.replacingOccurrences(of: "\n", with: "") else { return }
let tokenizer = NLTokenizer(unit: .word)
tokenizer.string = text
let tokens = tokenizer.tokens(for: text.startIndex..<text.endIndex)
let words = tokens.map({ String(text[$0]) })
guard words.count > 1 else { return }
var fixedLines = [String]()
var fixedTokens = 0
while fixedTokens < tokens.count {
let remainingTokens = tokens.dropFirst(fixedTokens)
let remainingText = String(text[remainingTokens.first!.lowerBound...])
let remainingLines = self.getLines(from: remainingText)
guard let brokenToken = remainingTokens.first(where: {
let word = text[$0]
return !remainingLines.contains(where: { $0.contains(word) })
}) else {
fixedLines += [remainingText]
fixedTokens += remainingTokens.count
continue
}
fixedLines += [String(text[remainingTokens.first!.lowerBound..<brokenToken.lowerBound])]
fixedTokens = remainingTokens.firstIndex(of: brokenToken)!
}
self.text = fixedLines.joined(separator: "\n")
}
}
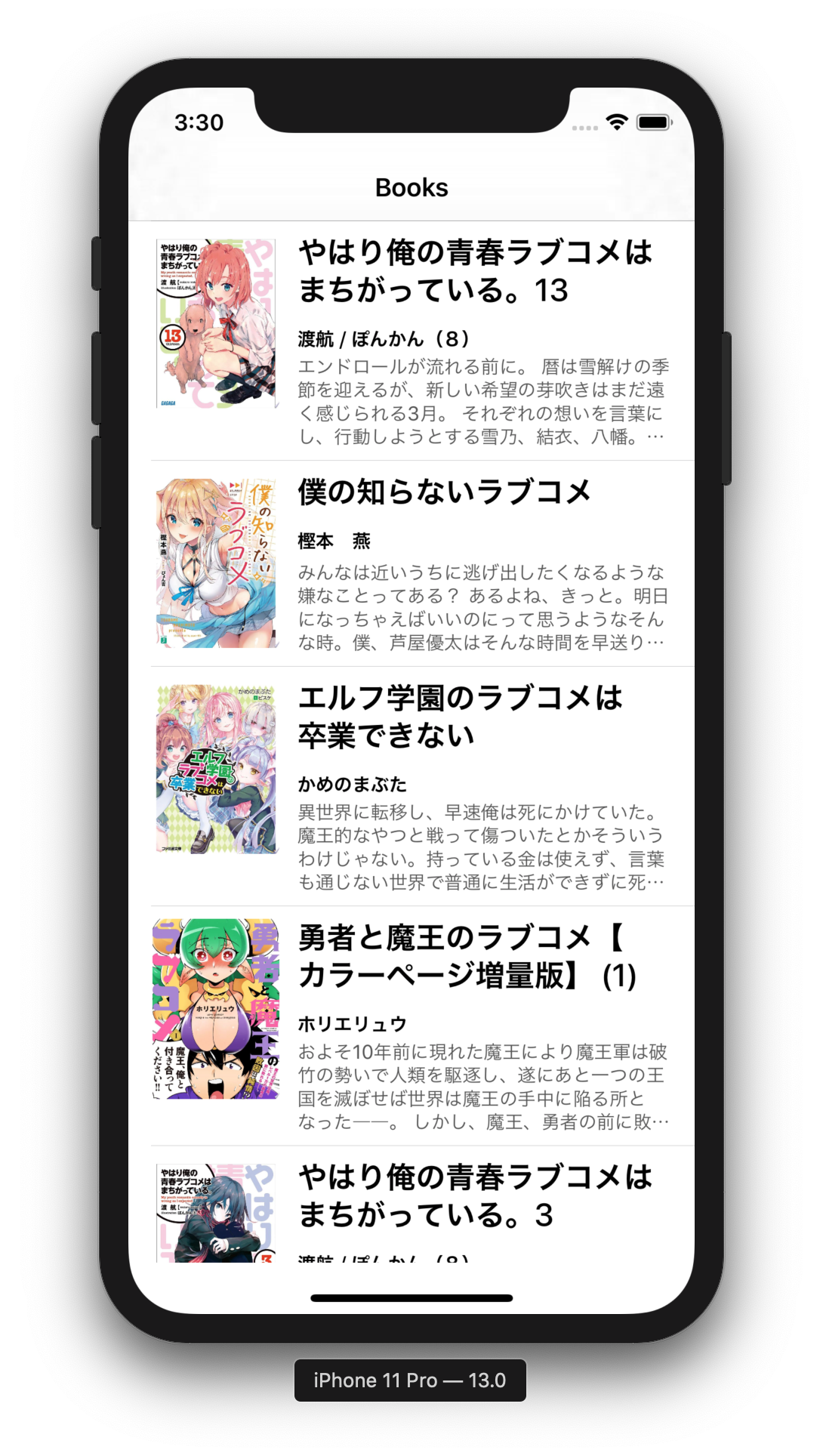
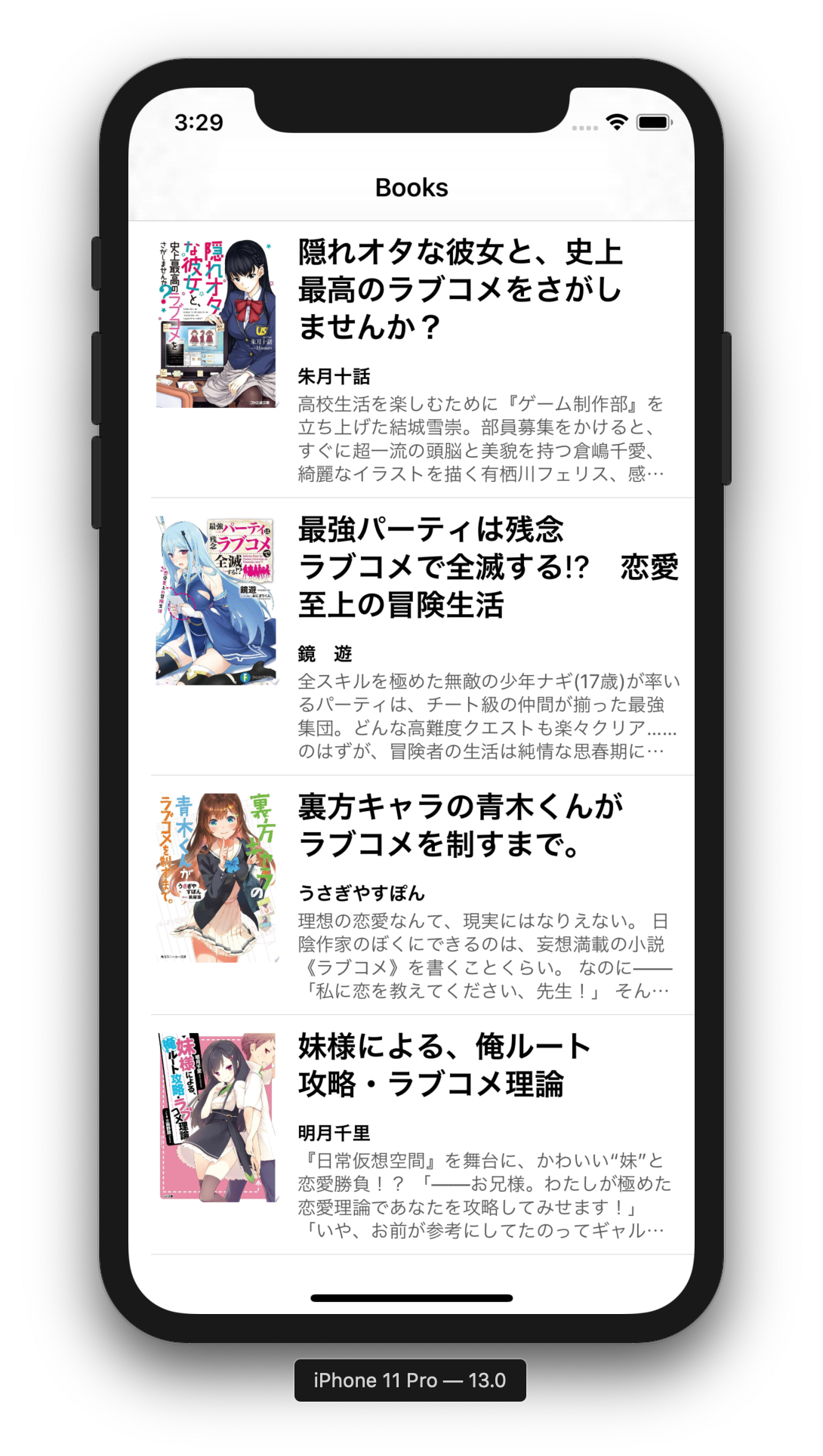
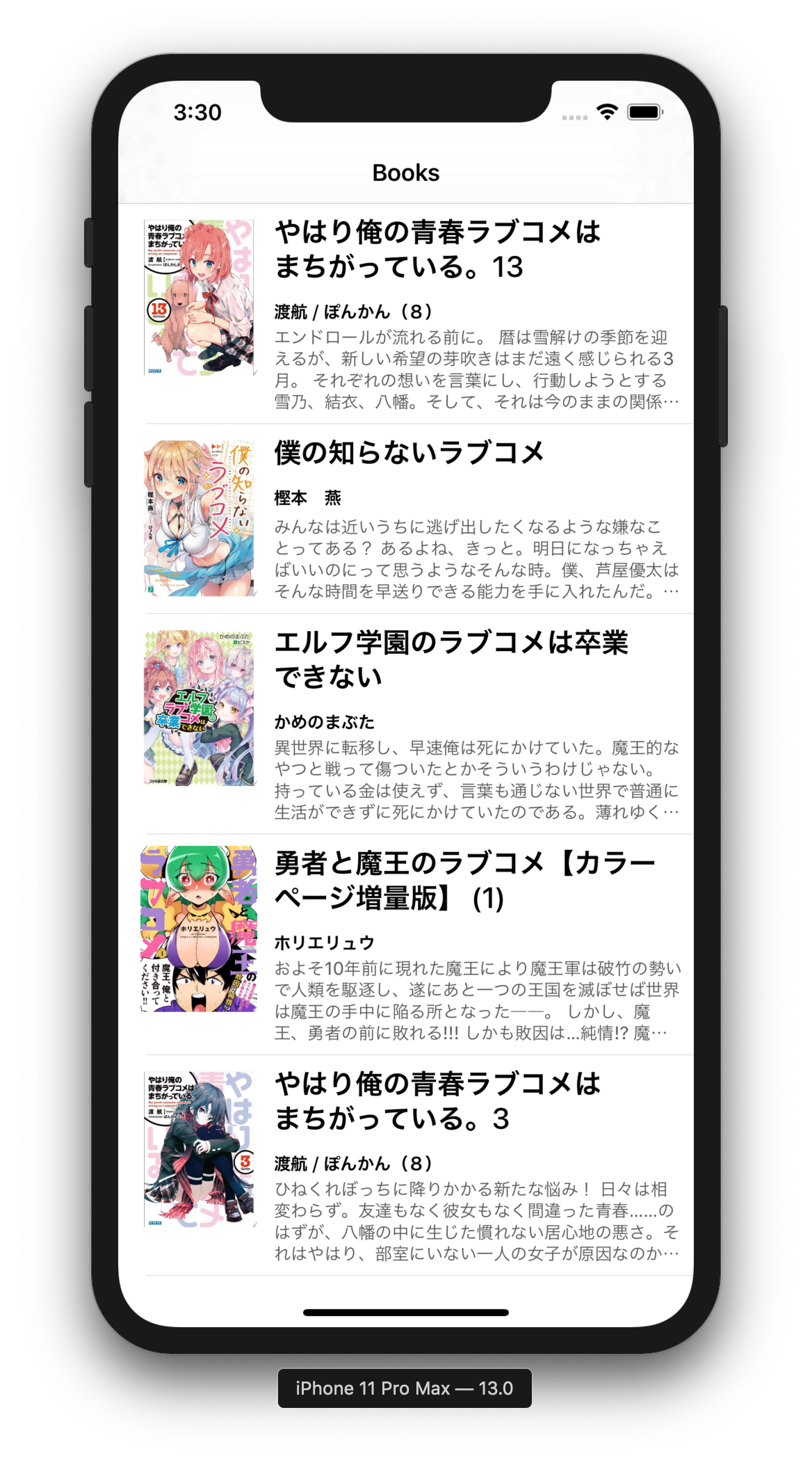
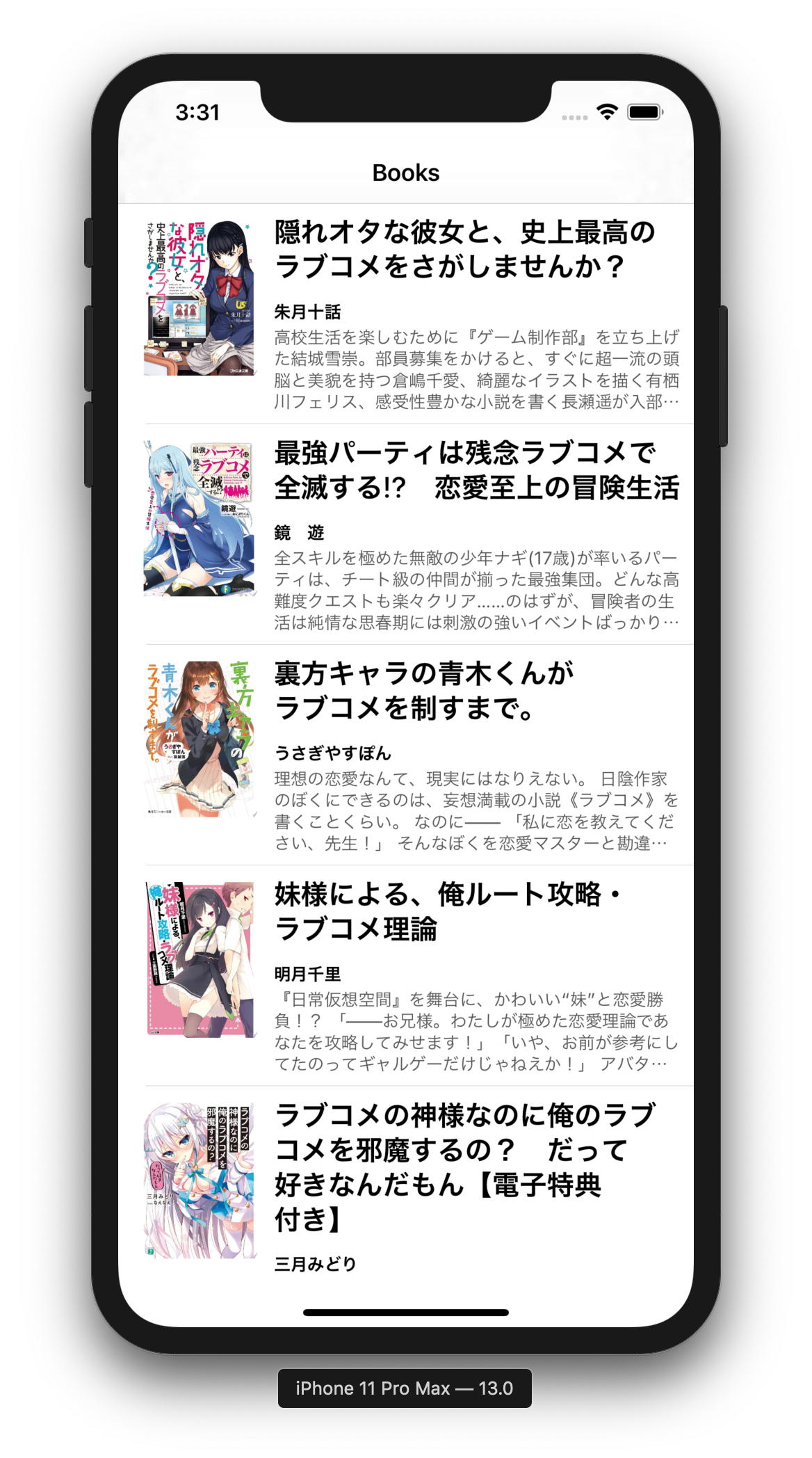
アプリを実行してみた結果は次のようになりました.
| iPhone 11 Pro | iPhone 11 Pro Max | ||
|---|---|---|---|
 |
 |
 |
 |
| Before | After | Size |
|---|---|---|
| やはり俺の青春ラブコメはまち がっている。14 |
やはり俺の青春ラブコメは まちがっている。14 |
11 Pro Max |
| 隠れオタな彼女と、史上最 高のラブコメをさがしませんか? |
隠れオタな彼女と、史上 最高のラブコメをさがし ませんか? |
11 Pro |
| 裏方キャラの青木くんがラブコ メを制すまで。 |
裏方キャラの青木くんが ラブコメを制すまで。 |
11 Pro Max |
思ってたよりも良くなっているような気がします(個人の感想です).
まとめ・感想
日本語のテキストの改行問題に対して自然言語処理で解決できそうか実験してみました.
- iOS の Natural Language Framework を使ってテキストを単語単位に分割した
- Core Text Framework を使って UILabel の改行位置を取得した
- 単語の中で改行が行われないように
\nを挟んでみた - 思ってたより良くなった(個人の感想です)
想像していたとおり,「史上\n最高」などは防げませんでしたが,改行問題をある程度解決することができました. ただし,実用に足りるかというと微妙かもしれません.
Apple の API で品詞の種類が取得ができなかったときは少しあせりましたが,なんにせよ Apple が「ラブコメ」を1単語として認識してくれていたのは良かったです.これがなかったら完全に詰んでいました.
2019年,完結おめでとうございます.アニメ3期もよろしくお願いします.
参考
- Google Books APIs | Google Developers
- Natural Language | Apple Developer Documentation
- Tokenizing Natural Language Text | Apple Developer Documentation
- Identifying Parts of Speech | Apple Developer Documentation
- NLTag - Natural Language | Apple Developer Documentation
- Core Text | Apple Developer Documentation
- CTFramesetter | Apple Developer Documentation
- Toll-Free Bridged Types